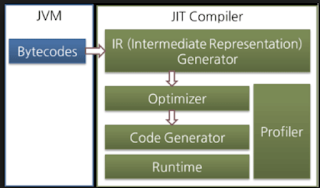
JVM Garbage Collection (GC)
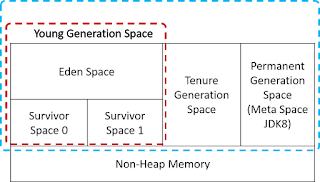
Java Heap Memory The Young Generation is where all new objects are allocated and aged. Tenure Generation stores old objects, which initially in young generation space, aged and moved to. Permanent Generation Space stores metadata required by JVM to describe classes and methods used in the application. JVM Garbage Collection Minor garbage collection (quick, stop-the-world) All objects started at young generation space, Eden space. When Eden space is full, GC runs in Eden Space, selecting all survivor objects and move them to Survivor Space 0. When Eden space full again, GC runs in Eden Space and Survivor Space 0, selecting survivor and move them to Survivor Space 1. When Eden space full again, GC runs in Eden Space and Survivor Space 1, selecting survivor and move them to Survivor Space 0.So and so. Every time an object moved from one survivor space to another survivor space, they age. When their age reach 8 (JVM 8), they are moved to Tenure Generation Space. G