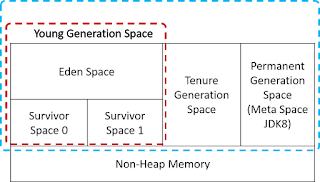
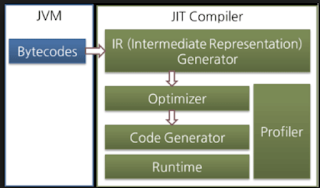
What does it mean by "volatile"? New JMM (1.5+) 1) Volatile variable reads from memory and write to memory instead of local cache Picture below shows example of a multi core system. Each CPU has cache, which is super fast memory locally for that CPU. For optimization purpose, many information stored in cache. But in multi threaded application which shared variable used, if each CPU update and fetch info from its own cache, value of the shared variable is wrong. Example: a counter By using volatile, every time volatile variable read, it is fetched from memory. Every time volatile variable written, it is pushed from L1 to L2 to memory. 2) Instruction which use volatile variable cannot be reordered 3) Volatile variable observes what happened For example, old value of w = 0 , x = 0 , f = true. f is a volatile variable. Now CPU1 updates x = 2 and f = false. As f is volatile, it is flushed to RAM. x is not volatile, however f observes that x changes as well, so...